Ethics and Legality
Ethics Case Studies
While some choices around computer security are clearly illegal or unethical, some are less clear cut. A number of computer security researchers have been charged or threatened with charges relating to their research, when they thought their actions were legal.
Consider this story:
I had just narrowly escaped being the subject of criminal charges filed by the United States Attorney's Office in Alexandria, Virginia. After I discovered and reported a disturbingly serious flaw in a computer system used by the General Services Administration (GSA) linked to the Department of Defense Central Contractor Registration (CCR) database in early 2006, I was summoned to Washington to be interviewed so that a federal prosecutor could determine whether or not to file criminal charges. The interview lasted several hours, with five GSA Inspector General agents and my lawyer also present. At the end, the U.S. Attorney decided to let me go. For that one interview, my legal fees were just over four thousand dollars.
That period of my life involved some of the most intense, prolonged stress that I have ever felt. Knowing that there is a realistic possibility that you could go to jail, knowing that your so-called crime was in fact borne of good intentions (and in my case, as the Ninth Circuit later clarified indirectly, did not even violate the law), knowing that it was incredibly unlikely that anyone would care enough to truly help (with legal arguments, legal fees, publicity, etc.), and knowing that you have caused your family the same stress, is crushing. The amount of cortisol in your blood is easily enough to cause unwelcome physical effects, some of which have followed me since, and will probably remain throughout the rest of my life.
Stories like this are why teachers get nervous teaching these topics, no matter how much they trust their students to do the right thing.
Each of you will be assigned one story from each group below. As you read, please ponder the following questions:
- What, if any, actions in this story would you consider unethical?
- What, if any, actions in this story do you think should be illegal?
- What things do you think the people involved could have done to achieve their goals while staying within legal and ethical bounds?
- What would you consider appropriate punishment? If relevant to your story, how does that compare to the punishments that were handed down?
- Group One
- Group Two
Ethical and Legal Resources
How can you stay safe legally and be considered an ethical hacker? Here are some attempts at guidelines:
- Read (at least) the last section, "In Sum, What Can I Do..." of the EFF's Coders' Rights Project Vulnerability Reporting FAQ
- Read (at least) the last section, "Code of Ethics for Ethical Hackers (An Example)" of Ethical Hacking Code of Ethics: Security Risks and Issues
- Obeying the Ten Commandments of Ethical Hacking
Additional Optional Resources:
- Conducting Cybersecurity Research Legally and Ethically
- Towards Community Standards for Ethical Behavior in Computer Security Research
- Ethical Hacking and the Legal System
- Reporting Vulnerabilities is for the Brave
Create Personal Ethics Rules
As the warning to this site says:
Computer security is a very important topic, and the more people understand it, the safer we will all be. However, this knowledge comes with risks. You could end up accidentally causing damage, perhaps far beyond what you imagine, if you attempt to gain access to systems that you do not understand as well as you think you do. You could end up in legal trouble, even if you have the best of intentions.
Do not use any of the information here to even attempt to gain access to resources or information that was not meant for you or try to prevent access to legitimate users of a system. Do not use any of the information here to attempt to skirt even the flimsiest security measures without the written permission of all owners/maintainers of the system in question.
In addition to my rules, what other boundaries do you want to set for yourself in order to feel comfortable about the actions you take while learning computer security? Here are some examples from previous classes:
- Have a plan of what you’re going to do, as detailed as possible, within the permissions you were given. Document changes.
- Record what you have done. (example: save commands you ran)
- Report any relevant findings.
- Don’t take money to hide information.
- Don’t publish sensitive information.
- Disclose information responsibly. Give organization time to fix. Be careful who you disclose to.
- Know where sensitive information is or might be and have a plan to avoid it.
- If something in a grey zone, check with the teacher.
- Check terms of service/policies that might be relevant.
- Avoid excessive resource use.
- Don’t act offensively for personal financial gain (exception of bug bounty programs).
- Don't save information you don't want to (or can't) be responsible for protecting.
- Follow a "least access" principle -- only access the minimal amount of resources needed to accomplish your task.
Threat Modeling
When assessing the security of the system, it is important to understand the threats you are trying to protect against. What outside attacks do you expect and need to prevent? What kind of resources do you expect outside attackers to have? How much can you trust your users, your employees, your system administrators, or other people with legitimate access? What sensitive information needs to be protected?
Having a clear threat model of the security that your system needs can help you make decisions about the countermeasures you employ. Some security features are low-cost and thus make sense to use even in low-risk environments, but others may be difficult to implement or make your software harder to use. You also want to make sure that you are directing your efforts toward the most crucial or vulnerable parts of your system first.
Another important thing to think about is the surface of attack. What are all the ways that an attacker could interact with your system? In general, you want to minimize this. Make sure that every service that can be accessed remotely is actually necessary. Minimize the number of people who have access to the physical hardware, the ability to modify the software, the permission to change the data, and so on. The fewer places you have to secure, the better.
Figuring all of this out is not easy. You may be caught off guard by a type of attack that you simply did not think of when coming up with your threat model. You might not realize the sensitivity of some of the information you had. You might underestimate the resources of your attackers or overestimate the trustworthiness of your users.
There are many resources that explain the most common vulnerabilities for types of systems, such as this list of Top Ten Web Application Vulnerabilities. This can be a good way to start thinking about how to protect your particular project.
There have been efforts to try to quantify how secure a system is but there is no accepted way to do this fully yet, as explained in the overview of this collection of research: “Today, cybersecurity remains an art, rather than a science. We can qualitatively assess improvement, but the truth is that even moderately precise measures of cybersecurity remain elusive in that there is no generally agreed upon system of measurement that is – even metaphorically – equivalent to the concept of generally accepted accounting principles.”
Cryptography
Cryptography Overview
Encryption is the act of making data hard to decipher unless you have access to some secret information, usually a key. Decryption is the act of turning encrypted data back into its original, readable form.
One-Time Pads
This is a symmetric key scheme that is secure no matter how much computational power you have available. The people communicating generate a truly random string of characters, with length equal to the number of characters in the message that they want to send. Then they use some operation (such as exclusive or) to combine each pair of characters -- one from the message and one from the random string. The output can only be decrypted with someone who has that same random string. This string is never used again to encrypt a message; future communication requires new random strings. As long as the secret string really is random, it is kept private, and it is never used again, this scheme is unbreakable.
Take some time to to decide if you buy the claim that this is unbreakable. Why would reusing the string make it easier to break? If this is unbreakable, why don't we just always use one-time pads?
Symmetric Key Cryptography
In symmetric key cryptography, people who are trying to communicate have a shared secret key. The same key is used to encrypt and decrypt information. Symmetric key algorithms are typically faster than public key algorithms for the same level of security.
Public Key Cryptography
In public key cryptography, each person has a key pair, one of which is made public and the other of which is kept secret. Data encrypted with the public key can only be decrypted with the private key, and data encrypted with the private key can only be encrypted with the public key. (In some systems, it only works in one direction; only one key can be used for encryption and one for decryption.) An advantage of public key cryptography is that the private key does not ever have to be shared with other people in order to use the system, whereas symmetric key cryptography requires that everyone involved has somehow received the key.
Cryptographic Hashing and Salting
A hash is a function that transforms variable-length data into a fixed length. A cryptographically secure hash function is a one-way hash: getting the original input given the hash output is about as hard as just trying every possible input until you get a matching output. It is also very hard to find two or more different inputs that will produce the same hash output. Small changes in the input data result in a large change in the output hash. Hashes are typically used to verify that data you received was not changed from the original: you can take the hash of the data and compare it to the hash of the original. It can also be used to store sensitive information, like a password, so that it can not easily be read but can be verified.
Salting adds some additional information to the input before hashing it, so that the same input in a different context will still have a different output hash. For instance, you might add time stamps to messages so that identical messages sent at different times have different hashes.
Cryptographically Secure Random Number Generators
A sequence is said to be truly random if there is no shorter way to express the same information other than giving the full sequence. For instance, 1,4,9,16,25,... could be described as "the square of the nth integer, and you could easily find the nth term without calculating the rest of them. For something like 0323513186846982..., there is no shorter way to express it, and there is no way to guess the next number with better than 1/10 probability, because any number could come next.
A cryptographically secure random number generator is one in which people with shared secret information can generate the same sequence, but someone without the secret information cannot guess the next number in the sequence even if they have seen all of the numbers that were previously generated.
Cryptography Purposes
Generally, use of cryptography falls into one of four categories[1]
Authentication
This gives you more confidence in the identity of the entity you are exchanging information with. Typically, this means that they prove that they have access to some secret information that you are reasonably sure only they would have.
Privacy
This gives you more confidence that no one other than the intended recipients can read the information being exchanged. Typically, this involves encrypting the message, so that it is hard to read unless you have access to some secret information.
Integrity
This gives you more confidence that the information being exchanged has not been altered in some way. Typically, this involves creating a hash of the information, often signed by with secret information that is likely only known by the legitimate sender.
Non-Repudiation
This gives you more confidence that someone cannot later say that they never sent information that they had in fact sent. Like authentication, this typically involves using secret information that only that person could have had. However, usually you need to include timestamps, because if the secret information is compromised (perhaps by the person who had it legitimately!), any information sent after the time of the compromise can be easily disavowed.
[1] categories from Schneier, Bruce Applied Cryptography: Protocols, Algorithms, and Source Code in C, Second Edition John Wiley & Sons, 1996
Cryptography Recommendations
It is important to keep up with and follow the latest recommendations from sources that are trustworthy new hardware comes out, it might become too easy to use brute force to reverse encryption done with a key size that was considered safe before. Researchers are continually finding problems in systems and their implementations, and using an algorithm or protocol with known flaws leaves you open to attacks.
For example, the National Institute for Standards and Technology maintains a set of recommendations, and there are a variety of tools that will give suggestions for key sizes, depending on your security needs.
Password Storage
If we are using passwords to authenticate users, then we need to remember the password for each user so that we can verify it each time a user logs in. This means that each password must be stored somewhere. If someone were to break into the system, they could potentially get all of our user passwords. What should we do?
We could encrypt our passwords with some secret key, and unencrypt them to compare to what a user types when logging in. But if someone has broken our system, they can probably get this private key as well, and we are back to all passwords being compromised. A better solution would be one in which the system never needs to have the password in cleartext.
Enter the one-way cryptographically-secure hash. If we store the hash of the user's password, then there is no (feasible) way to get the password from our system. When the user enters a password, we hash what they entered and compare this to the stored hash.
But wait! Users often choose common passwords. Looking at compromised password databases, 123456 or password have topped the list of most common passwords for years. The same password means the same hash, which means that all someone needs to do is hash common passwords with common hashing algorithms and compare them to the stored hashes and they can figure out the passwords for a large number of the accounts. In fact, people have created lists of these hashes, called rainbow tables which contain the most common passwords hashed by popular hashing algorithms.
To help solve the rainbow table problem, we can use salts. A salt is some data, different for each user, that is added to their password before hashing. Typically salts are long random strings -- long just to make sure it really is unique to that user. The salt is not secret, unlike the password, and can be stored in plaintext. It is just meant to make sure every user has a unique hash even if they have used the same password. Someone could still find an individual user's password by trying the hash of a bunch of common passwords with the salt to see if they match, but this doesn't help them with any other users. They have to go through the full process with each one, and thus it takes them a lot longer.
Another thing that helps with security is to use a slower hash, like bcrypt, or one that requires a great deal of memory, like scrypt, or one that requires a lot of computation, uses a lot of memory, and requires a certain number of threads, like Argon2. Since legitimate users only need to run the hash once (or as many times as they mis-type their password) when they log in, the slowdown will likely not matter to them. Attackers, on the other hand, will be very inconvenienced because they are running a huge number of hashes to try to find a match for each user.
In summary, for password storage:
- choose a long random salt that is different for each user
- store the salt and the hash of the password+salt
- do not store the password
- use a hashing function that requires a lot of resources
- don't allow users to choose short or common passwords
Diffie Helman Key Exchange
A key exchange is a process for creating a secret key in a way that two people can each get the key wihtout ever sending any information that would allow someone else to figure out the key. Once the key is exchanged/created, it can be used for symmetric key cryptography. The mathematics behind the exchange are the same as those in public key cryptography.
Read the details in the top answer to this request for an explanation of the process.
Digital Signatures
Digital signatures provide a way for people to verify data using public key cryptography. If I can successfully decrypt data with a public key, then I know that it had been encrypted with the corresponding private key. People or organizations can make their public keys known so that they can send verified information. As long as they keep their private keys secure, I can be reasonably sure that the data came from them.
One common use of digital signatures is for web certificates. Web sites have certficates that tie their public key to the site, so that during the initial key exchange with the site, its identity can be verified. These certificates themselves are signed by certificate authorities, organizations that verify that the public key is held by the owners of the site. Thus, you just need to know and trust the public keys of these small number of CAs and then you can reasonably trust that the data is coming from the site you intended to visit.
HTTPS, SSL, and TLS
TLS (Transport Layer Security)
TLS allows for two-way communication that cannot be read or unnoticeably altered (that is, it provides privacy and integrity). It uses symmetric key encryption for privacy and a message authentication code/digital signature for integrity.
The TLS handshake uses a key exchange algorithm to generate a key for symmetric key encryption. It may authenticate one or both entities communicating, though this is not required.
For more information, see this explanation from IBM.
SSL (Secure Sockets Layer)
This is the old name for TLS. You'll still often see this used.
Secure HyperText Transfer Protocol (HTTPS)
HTTP is the protocol by which web pages are sent. HTTPS uses TLS to provide more security to web communication. When you visit a website with https as the protocol in the URL, the web browser authenticates the site using the site's signed certificate and then performs a key exchange that will allow all future traffic to that site to be encrypted using the key that is created.
Sources/For More Information:
- https://tools.ietf.org/html/rfc2818
- https://tools.ietf.org/html/rfc2246
- http://security.stackexchange.com/questions/5126/whats-the-difference-between-ssl-tls-and-https
Symmetric Key Cryptography
Symmetric key encryption gets more security for smaller keys than does public (or asymmetric) key encryption. Smaller keys means less computation, so symmetric key encryption is faster for the same amount of security. However, it requires that both people have the same key, which is a big downside. Thus typically, systems use public key encryption initially to exchange a key that they can then use for symmetric key encryption to continue to send messages.
To see an example of a relatively simple (and easily broken) symmetric key encryption scheme, check out the Playfair cipher.
Currently, the most trusted symmetric key cipher (at least in the US) is probably AES.
- Some history of AES and explanation of what it is used for
- An overview of the math involved in AES
- Deeper dive of the math to implement AES
- Even deeper dive into AES
Bitcoin
Bitcoin makes extensive use of cryptographically secure hash functions in order to process new transactions. The computers processing new transactions try out different salts with the transaction data in order to find partial matches in the output hash (the partial match is set depending on how fast new bitcoins should be issued). The first processor to find the partial match is rewarded with new bitcoins, and the transaction data becomes part of the blockchain of verified transactions.
For more information about this process, see this explanation and this explanation. The idea is that as long as more than half of the computers processing the transactions are being honest, then the correct transactions will go through. The 51% attack involves getting more than half of the processors to verify the same fake transactions.
SHA-256
This is a simplified explanation of the SHA-256 algorithm as described in FIPS 180-4 (FIPS are official US government standards; it stands for Federal Information Processing Standards). I also looked at this implementation to check my understanding.
Preprocessing
The initial hash value is
6a09e667
bb67ae85
3c6ef372
a54ff53a
510e527f
9b05688c
1f83d9ab
5be0cd19
(This is the first sixty-four bits of the fractional parts of the square roots of the ninth through sixteenth smallest prime numbers.)
Take the input that is to be hashed. Add a 1 bit to it. Then add enough zeros so that the total length of the message will be equal to 448 mod 512. Add the length of the original input, in 64-bit binary. The length of the input should now be a multiple of 512 bits.
Computation: Schedule
For each 512 block of the preprocessed message:
- First, take the first 16 32-bit sections of the message and put it in a new output array we'll call "schedule"
- Then, 48 times, get the 2nd-to-last, 15th-to-last, and 16th-to-last 32-bit sections of the current schedule
- take the second-from-last section and
- rotate its bits 17 places
- rotate its bits 19 places
- shift its bits right (replacing the left bits with zeros) 10 places
- xor together the output of the two rotations and the shift
- add this on to the schedule
- take the fifteenth-from-last section and
- rotate its bits 7 places
- rotate its bits 18 places
- shift its bits right (replacing the left bits with zeros) 3 places
- xor together the output of the two rotations and the shift
- add this on to the schedule
- add the 16th-to-last section to the schedule
- take the second-from-last section and
- Set variables a,b,c,d,e,f,g,h to each byte of the current hash, respectively. Remember that the first time around, the hash will have the initial values set in preprocessing.
- 64 times
- change a through h in the following way:
- save a variable t1 as the sum of
- h
- the following values xor'ed together
- e rotated right 6 places
- e rotated right 11 places
- e rotated right 25 places
- the following values xor'ed together
- bitwise and of e and f
- bitwise and of (not e) and g
- the 32-bit section of a constant K (defined in section 4.2.2 of the paper) corresponding to how many times we've gone through this loop. That is, first use the first byte, then the second, ...
- the 32-bit section of the schedule that we defined above corresponding to how many times we've gone through this loop
- save a variable t2 as the sum of
- the following values xor'ed together
- a rotated 2 places
- a rotated 13 places
- a rotated 22 places
- the following values xor'ed together
- the bitwise and of a and b
- the bitwise and of a and c
- the bitwise and of b and c
- the following values xor'ed together
- set h to g
- set g to f
- set f to e
- set e to d + t1
- set d to c
- set c to b
- set b to a
- set a to t1 + t2
- save a variable t1 as the sum of
- change a through h in the following way:
- then update each hash value, adding the corresponding variable (a for the first, b for the second,... h for the last) to the previous value of the hash
Now, we pull together each of our eight 32-bit hash pieces to get the final 256-bit output.
Elliptic Curve Cryptography
Earlier, we looked at a Diffie-Hellman key exchange based on large number factorization, exponentiation, and modular arithmetic. RSA public key cryptography is also based on the types of operations.
Another way to implement public key cyrptography is using elliptic curves. In this case, the secret information is how many times you have repeated an operation to move around the curve. It is very hard to figure this out just knowing the ending point on the curve, but easy to verify if you know the secret information.
For more information, see
- a primer on ECC
- an example of using the ecdsa library for ECC
- a simplified implementation of ECC without modular arithmetic
- a more complete mathematical description of ECC
Cryptography Exercises
Exploratory Practice
Try to use some of the cryptographic tools we're been talking about. Keep notes on what you do and learn. Here are some suggestions for things to try:
- Send an encrypted email to another person in the class, such that only they can read it. What tools exist to let you do this, and how well do they work?
- Send an email to another person in the class that has been cryptographically signed. What tools exist to let you do this, and how well do they work?
- If you have a website that does not currently support https, use Let's Encrypt create a certificate for your site.
- Figure out what Certificate Authorities your browser trusts.
- Hash some string (or have a partner do it). Test out the properties of the hashing function, noting how much the output changes from small input changes. Write a program that will try some brute force solution to figure out the string by finding a matching hash. Observe how the length of time varies based on the string you use and the way you structure your search. Try this with different hash functions, to see the differences in speed.
- Look at some different accounts you have and see what level of security they provide.
- Try turning on two-factor authentication, if you have that option.
- Look at their security questions and figure out roughly how many different options there are, assuming you answer honestly. For instance, if it is asking for the model of your first car, get an estimate of how many different car models have ever been made.
- Think about how secure your password is, relative to how attackers would try to guess it. Is it a relatively common word? Is it in the dictionary? Is it all lower case letters, or do you also include uppercase letters, numbers, and/or symbols? Think about how large a search space is needed to find your password. Do some research on current recommendations on password length and generation.
- Try encrypting and decrypting files. What are the different tools out there that provide this service? What do encrypted files look like?
- Generate a public/private key pair for yourself. Put the public key on our test laptop so that you can SSH into your account without typing a password. You could also use this key for your Github account, if you have one.
Design a System with Cryptographic Components
Choose a scenario in which different entities (people or machines) need to pass sensitive information between them. Design a system that makes this information passing more secure.
Work alone or in a group of up to three people.
Required: Include a description of your threat model. What are ways that your system might be compromised? Which of those is your design addressing? It's OK not to handle everything, but you want it to be a deliberate choice.
Required: Describe the basic cryptographic components that are part of your design and how they are used. (e.g. "a public key algorithm with large enough keys to likely be secure through 2030"). See, for instance, this keylength recommendation tool.
Required: Describe the steps of your protocol, e.g.
- Alice sends a message to Bob, encrypted with his public key.
- Bob sends the same message back to Alice, encrypted with her public key.
Optional: Implement some pieces of your system in code. You can either use cryptographic libraries or attempt to implement some of your own.
Here are some examples of scenarios that you could use. Some of these are large systems, so you don't want to describe the whole system, but just a specific piece of it.
- check-in/check-out system at a school
- security gate at parking garage
- electronic money transfer
- password storage system
- chat
- software update system
- voting machine
- medical devices with wifi or some other communication
- exchanging information with an undercover informant
- IT department at a school or company
Example Protocols
- Protocol for access to servers for new employees and departing employees
- Protocol for browsers authenticating websites
Yours do not have to be this long or wordy. These are longer to make sure they would be understandable.
Input Validation
Dangers of Eval
Eval is the process of taking a string of text and evaluating it as code. Some programming languages have a function named eval that will take a string and evaluate it as code. For instance, in some languages something like
eval("5 + 2")
would evaluate to 7 (the numerical value; not a string).
We need to be very careful when we are about to interpret a string as code, whether it is a database, browser, interpreter, or anything else doing the interpreting. We cannot just put user input into an interpreter without sanitizing or validating it first. If possible we want to avoid interpreting it at all by avoiding the use of eval altogether. See Eval Really Is Dangerous and Never use eval()! and Eval Isn't Evil, Just Misunderstood for some more explanation of what can happen as well as some examples of when eval is used unnecessarily.
It is not always obvious when strings will be evaluated; avoiding the command named eval is not always enough. We always want to be very careful about what we are doing with user input, making sure that it is never interpreted unless we are completely sure that is necessary and we have validated the input as much as possible. Some examples of a hidden eval are using the innerHTML property to set the content of an HTML element or using the input() function in Python 2 (this has been fixed in Python 3).
Cross-site Scripting
Cross-site scripting (often abbreviated as XSS) becomes possible if you display user input on a web page without validating it in some way. Browsers are going to evaluate the input as code if you include it in certain ways.
Web browsers need to go through each element on a web page and run any HTML, CSS, and JavaScript found within. If one user's unvalidated input is being displayed to other users (for instance, in a comments section), they are now able to run JavaScript in the browser of the other users. This might give them access to private information that your site is sending to be displayed for the other user.
Fixing this typically involves some kind of sanitization. Most programming languages have some library calls that will escape symbols that are meaningful in HTML so that they will instead just be displayed as characters. Even better is to avoid setting the innerHTML property with user input, if it is not necessary to evaluate and render the HTML tags in the input; there are other ways to set the content that will treat the HTML tags like plain text and not as code or markup.
See https://excess-xss.com/ for more detail and examples (but note that many of their examples will not work for the XSS exercise in the assignment, because the code for the assignment is just an HTML file and not running through a server).
Database Injection
Programs frequently store information in databases. Databases allow programmers to write queries that ask for particular subsets of the data stored. For instance, an online shopping site might need queries that allow them to find all items in a certain department with certain words in their description that can ship to the location of the current user, ordered by customer rating first and then by price. Most of the information for this query came from users at one point or another (their address when they signed up, the search terms just now, etc.), which means that we cannot just trust it.
Simplifying our example a bit, let's say we wanted to look for any book whose subject is "Computer Security". In a query language like SQL, this would be something like
SELECT title, price, rating, subject
FROM products
WHERE type='book' AND subject='Computer Security';
In another popular type of database, MongoDB, it might look like
products.find(
{type: 'book', subject: 'Computer Security'},
{title: 1, price: 1, rating: 1, subject: 1}
)
If all our queries were like this, where we knew ahead of time what we were searching for, that would be great, because we can write everything out like above. But usually, we are going to be wanting something more like this
query = "SELECT title, price, rating, subject " +
"FROM products " +
"WHERE type='" + type + "' AND subject='" + subject + "';"
because had the user enter what type and subject they are searching for and we stored those in variables. But now we have a problem. What if the user typed in for the subject
; DROP TABLE products;
The first semicolon ends our select statement. It makes the statement malformed, which is an error, but typically the database will just move on to the next command, which the user supplied. In this example, it is a drop command that tells the database to delete all of the information in our products table!

While the person in this XKCD comic should have picked a better way to let the school know, she is right that input sanitization/validation is really important! Sanitization and validation typically involve
- getting rid of any malformed or uninterpretable input
- removing or escaping anything disallowed because it has special meaning in the language in which it will be interpreted
- checking that the user's input satisfies your assumptions and expectations (e.g. that the input to a date field is actually a date that is in a reasonable timeframe)
These checks will look slightly different in each language/database combination. Often, there are libraries that will perform many of these safety checks for you. One example of this is using SQL prepared statements. These are objects that are partially compiled and just waiting for some parameters of a specified type. Putting in something totally different causes no response or an error response and cannot be interpreted as the start of a new command. Here's an example in PHP from W3 Schools:</span>
// prepare and bind
$stmt = $conn->prepare(
"INSERT INTO MyGuests (firstname, lastname, email)
VALUES (?, ?, ?)"
);
$stmt->bind_param("sss", $firstname, $lastname, $email);
// set parameters and execute
$firstname = "John";
$lastname = "Doe";
$email = "john@example.com";
$stmt->execute();
The software will now specifically verify the values of the variables firstname, lastname, and email before passing them in to replace the three question marks, in order. The bind_param function allows you to specify what type each variable should hold (all strings, in this example).
Similarly, by default MongoDB will run some checks on all requests. There are also packages to help with sanitization to guard against certain kinds of attacks.
Buffer Overflows
A buffer is a certain amount of space that has been allocated in memory.
I might, for instance, need to hold some messages as they come in to my server, until I have time to process them. If each message is 50 bytes, and I ask for a buffer of 1000 bytes (50 * 20), I am OK if I have up to 20 messages waiting.
What if I get up to 21? I should have something in my code that notices that the buffer is full and just ignores the message or deletes an older one to make space for it. What if I forgot to do that or I am so confident I would never have that many messages backed up that I don't bother to check? Many programming languages would throw an error if I attempt to store something at position 1001 in the buffer. While this is not a great outcome (it could result in a denial of service if it causes my server to go down), the damage is fairly limited.
But what about languages that don't check if the index I asked for actually exists in my buffer? The C language, for instance, does not have many extra features or failsafes, which can make it easier to write fast code since it avoids the overhead of additional checking, but can also make it easier to write unsafe code. In C, I can ask for a certain amount of memory to be set aside for my buffer, and I get back a pointer -- the address of the beginning of the memory for my buffer -- and that is it. It is entirely up to me, the programmer, to keep track of where the buffer ends and make sure I don't go past that.
The Problem
What if I do go past that? Well, I would start reading or writing data to parts of the memory that are used for other things in the program. This is a buffer overflow. This might just cause simple errors where variables are overwritten and have the wrong values. However, one of the things that a program stores in its memory is where to find the next block of code to execute. If an attacker realizes that their input is put into a buffer without any checking, they could try to deliberately write that location in the memory so that their own code would be executed instead of my code. The area of memory that contains (among other things) the address of the code to execute next is called the stack, so a buffer overflow in that area is called a stack overflow (yes, that is where the name of the website comes from).
Similarly, if I take as input the amount of buffer space to read and don't check that it is less than the size of the buffer, I may end up sending to an attacker private information that they shouldn't have access to. This was the cause of the infamous Heartbleed issue.
The Fixes
For you as a programmer, there are a number of things you can do.
- The main thing, our theme in this unit, is to check user input. If the user is giving you a size, check to make sure that the size is smaller than your buffer (and positive!). If the user is giving you data, only save as much as will fit in the buffer you have (or make the buffer bigger).
- Don't use a language (like C or C++) that doesn't have protections against unsafe memory access unless it is absolutely necessary.
- When using C++, use the C++ string and vector objects rather than C-style strings and arrays, unless your code really must take up less memory or computational power (Does it really need that? Did you run it through a profiler?). In general prefer the C++ standard libraries to the C standard libraries.
- When using C, always use the string/array/list functions that take a size argument. Without a size, C will keep going until it finds a null byte (that is one with value 0) marking the end of the array. If you forgot to put a null byte at the end or if it is overwritten, the C function will keep going, using parts of the memory that are not actually part of your array. The functions that take a size, in contrast, will stop when the size limit is reached. Specifically, this means you should be using strncpy instead of strcpy, strncat instead of strcat, snprintf instead of sprintf, and so on.
There are also things that compilers, operating systems, and processors do to mitigate the danger from buffer overflows. The addresses for where to get the next sections of code that will be executed are usually stored on a structure called the stack. Writing a buffer overflow that overwrites these addresses is called smashing the stack. Many system-wide mitigations focus on prevent stack smashing. This post has details about many of these and links to papers about what they can and cannot prevent. Here are a few examples:
- Stack canaries are special values that are added into the stack. If these values are not present (perhaps because something overwrote them), the program will not be allowed to run.
- Executable space protection allows part of the memory to be marked non-executable. All user input should be put in those parts. Now, even if an attacker manages to overwrite the addresses to point to their own code, it still won't run, because it is in a part of memory that is not allowed to run. This can be implemented in hardware, with the NX or non-execute bit.
- Address space layout randomization (ASLR) makes it harder for an attacker to reliably execute an attack that overwrites a specific part of the memory, because things will move around randomly each time.
Specially Crafted Files
This example comes from the book A Bug Hunter's Diary by Tobias Klein[1].
This vulnerability is less common than the ones we've studied so far, but it provides an interesting look into how computers work and how sometimes relatively straightforward errors can become dangerous security risks.
The vulnerability happens through something you might not have thought of as user input: a file. Remember, files are generally coming from the user, so you cannot trust them! They should be treated like any other user input.
In the case described in the book, the code reading in a media (audio/video) file took metadata about buffer sizes from the file and stored them in signed integers. A signed integer is one that can be negative or positive. Unsigned integers can only be positive, and are typically what you want to use for sizes. In a signed integer, the highest bit is the one that specifies whether the number is positive (if the bit is zero) or negative (if the bit is one). For a one-byte number, 255 would be 255 as an unsigned byte, but -1 as a signed byte. For more information read about Two's Complement numbers. Putting in a size for the buffer that is big enough to set the high bit of the integer means that the buffer now has a negative size. A negative number is going to be less than whatever the max size of the buffer is, so any checking of the buffer size is defeated.
This negative number trick allowed the user to overwrite multiple areas of memory with information they put in the specially created file. Since some of this memory contained pointers to the next block of code, the user could now execute whatever code they want.
[1] Chapter 4, "Null Pointer FTW" pages 51-70
Null Pointer Dereferences
This example comes from the book A Bug Hunter's Diary by Tobias Klein[1].
This vulnerability is less common than the ones we've studied so far, but it provides an interesting look into how computers work and how sometimes relatively straightforward errors can become dangerous security risks.
As we saw in the Buffer Overflows section, frequently computer programs are dealing with pointers or references to different areas of memory that hold the objects for that program. We generally want to get some particular field in the object, with syntax like person.name or person->name, depending on the language. If person is null (or zero or none), the deference fails, and we get an exception or crash. If that object is coming from user input, the user could deliberately cause the pointer to be null, creating a denial of service when the program or system crashes.
However, there is an even greater danger. A null pointer deference usually causes a crash because it is essentially asking for memory position zero, which is almost always not available to the program. However, if the malicious user was able to create memory at position zero, which is possible on some systems, they could put in their own object in this memory space, and their object would now be dereferenced by their null pointer. If that object was being used to provide addresses for future function calls, the attacker can now control what code gets executed in the future. They have gained control of the program.
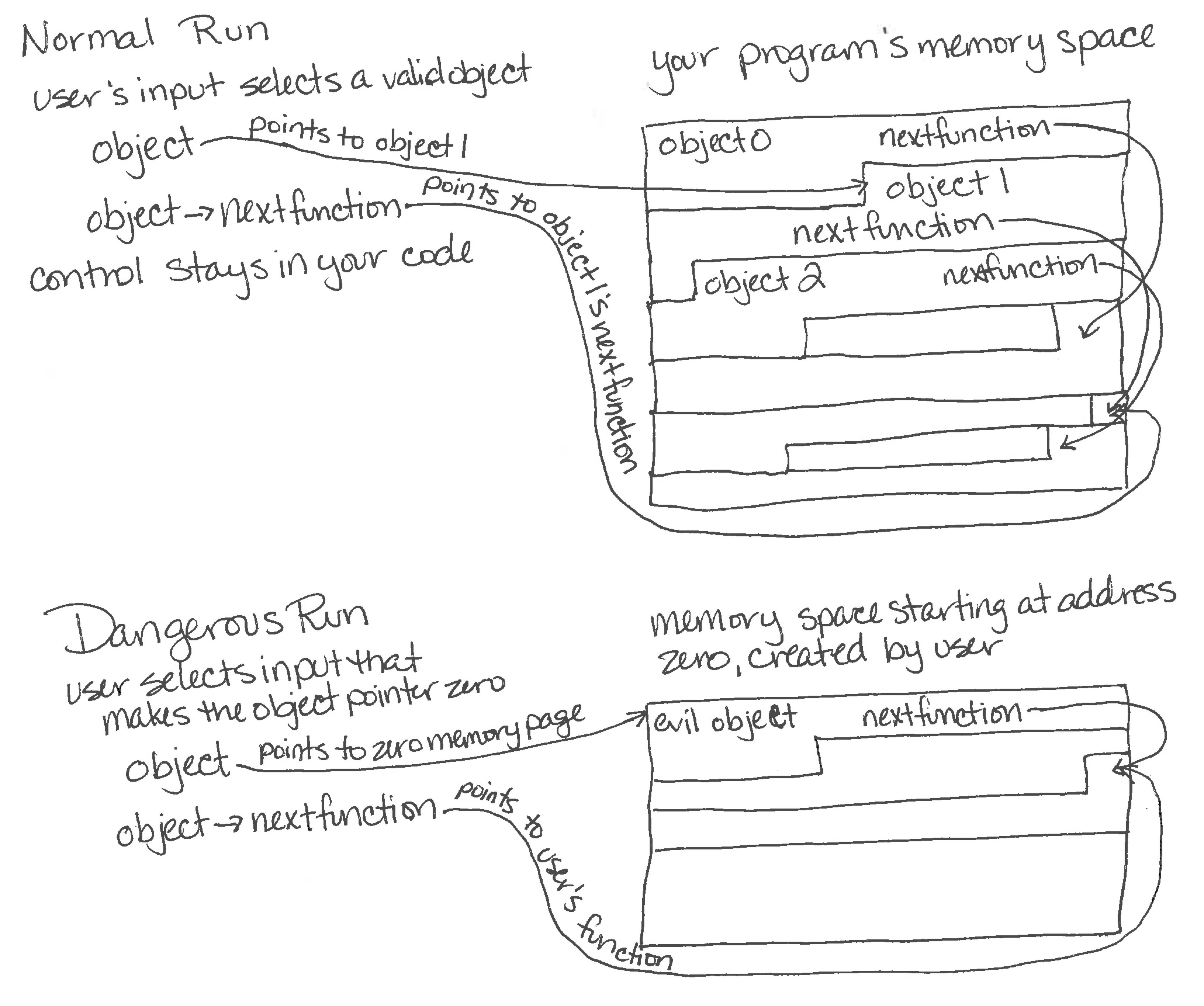
[1] Chapter 3, "Escape from the WWW Zone" pages 25-50
Input Validation Exercises
Show your understanding of at least one of the potential input validation failures discussed above by
- writing code and notes demonstrating a successful break on a system meant for testing -- not on a production system and not on one maintained by someone unaware of what you are doing
- writing code and notes that demonstrate changes that would prevent your break
- giving the name of a specific law you might be charged with if you were to do this on a system without permission, with a citation to a story or source that demonstrates why that law might apply
Below are different suggestions of test systems that you could use for this assignment. You could similarly use an exercise from a computer security practice site, like the ones listed here.
- Eval: Suppose someone has a very simple Python 2 script:
favorite = input('What is your favorite number? ') print 'I like the number {}, too!'.format(favorite)They claim that it's a harmless script and it would be safe to let anyone interact with it. Show examples of input to this program that would give you access to their information (e.g. the contents of a file on their machine). - Cross-site scripting: Go to this page and try entering some comments. Make your comments fancier by using some HTML tags. Write a comment that will cause some JavaScript to run.
- Database injection: In the classroom during this time, a minimal webserver will be running on port 3502 of a class laptop, and we'll provide the IP address then. Go to http://<ip>:3502 and attempt to log in through the form. If the site is down, please let the teacher know ASAP. Since the code was deliberately made vulnerable, this meant avoiding many libraries that would have made it more stable. You do have permission to try to hack this computer in any way you would like, but please do your best not to do anything to it that would make it hard for other students to use it. Remember not to put anything private on there (this includes typing a password for any other account)!
- Buffer overflow: If you haven't installed the XCode command line tools before, in Terminal run
xcode-select --install
If you haven't used C before, spend some time experimenting with the test program pointer_demo.c to get some sense of how pointers work. To compile and run this program, run the following two lines in Terminal, in the directory where you downloaded the file:gcc -o pointer_demo pointer_demo.c ./pointer_demoTake a look at the buffer_overflow.c example code. You can compile it and run it usinggcc buffer_overflow.c ./a.out some_passwordFirst, read the code to figure out what the actual password is and verify that you are granted access if you give this password. Now, compile it with some extra flags that will disable various security measures:gcc -fno-stack-protector -D_FORTIFY_SOURCE=0 buffer_overflow.cFind a password that is not the correct one but does grant you access. (This code comes from this stackoverflow post which has one possible buffer overflow solution, though it doesn't work on all computers, because it depends on how the compiler lays things out.)
Authorization
In computer security, we often talk about auth, which can expand to either authentication or authorization.
Thus far, we've really only talked about authentication, establishing an entity's identity through their possession of some secret information (password, private key of a asymmetric cryptography key pair, fingerprint pattern, etc.). An entity might be a human, a device, a program (called by a user or another program) -- anything that might be accessing parts of your system.
Authorization is about deciding what an entity should be allowed to do once we know who they are or what group they are part of. There are many different authorization ideas and systems. They are typically fairly tied to specific applications, unlike authentication systems which tend to be more easily used by any type of program. Authorization is about giving specific permissions or privileges to specific entities. This is sometimes done through ACLs, Access Control Lists.
There are a few guiding principles to think about when designing the authorization for your particular use case.
-
Separate privileges as much as possible and run with the least privilege possible. The more things an entity has access to, the more opportunities they, or someone who has manage to gain control of their identity, have to attack the system.
Does your webserver need to run as root or as your user, both of whom have access to things the webserver does not need, or could you create a less privileged user to run it? Because ports 80 and 443, the standard ports for web servers, can only be accessed by superusers on UNIX-based systems, many sites are served on a higher port number so that the server does not need to run as root. Another script with root access has the sole job of forwarding the traffic from the server port to 80 or 443.
As another example, Mobile OSes have very specific permissions so that apps can be given only the ones they need and no others (e.g. iOS, Android). Similarly, some Linux systems have capabilities that can be given to programs rather than full root access.
Note that this is a balance! If two privileges are almost always used together, it might not make sense to make your users always have to ask for both, possibly leading to users not being able to do what they need to do if the programmer has obtained one permission but forgotten the other. Don't split things up unnecessarily.
-
If asking a human to authorize an action, make it clear what they are authorizing. If users don't understand what you are asking, they may end up just not doing what they originally wanted to do, or (even worse) they may begin ignoring or turning off your security.
Early on, Android permissions were often confusing and scary for users, because it was hard to understand why apps would need certain permissions when installing them. Fortunately in more recent versions, permissions work as they long have in iOS, with authorization requested when the app needs it rather than at install time. Windows Vista had a similar problem, frequently asking users to give it permission to run scripts with names like asedt6y1es.exe, causing many users to turn that off those prompts entirely, which was sort of like telling OSX to just run everything with sudo.
-
Check authentication and authorization at every entry point. It is usually fairly easy to remember to check at the beginning of a system running to see who is running it and what permissions they have. In something like a web server, however, an entity might enter at any URL. Frequently, people have made the mistake of thinking that since the my.example.com/admin link was only on the home pages of admin accounts when the user was logged in, that only admins would access it. However, attackers might think to try that URL directly (a URL interpretation attack), so that page also needs to check that the user is logged into an account with admin permissions.
-
Be careful about ordering allow and deny directives. Many systems are allow-only: either the entity has been given explicit access, or they can't use the resource. In other cases, you can specify entities that you want to deny, giving everyone else permission.
Sometimes, these allow and deny lists are read in order: I might deny all students access to my pages teaching people how to hack systems, and allow students in my computer security class. Since the allow comes second, it overrides the deny access just for the students in my class. If I put the lines in the other way around, no students would have access. Firewall systems like iptables work this way when going through accept and drop rules. In other systems, for instance Apache directives, allow and deny are processed separately, so that my security class would get access no matter the order of those two control lines, because denies are always processed first.
If security is a priority for the system you are working on, it is almost always better to deny by default and only allow a small set of specific people or groups rather than to allow by default and deny some specific people or groups.
Authorization Exercises
Respond to at least one of the authorization-related prompts below. Take notes as you do your research.
- On UNIX-based systems like OSX, directory and file permissions are generally made up of three groups of three: read, write, and execute permissions for the individual owner, the group owner, and everyone else. You can view the permissions in Terminal with "ls -l" and change the permissions in Terminal with chmod. Create a test file and see what permissions it is given by default, then try changing the permissions on it. Take a look at the permissions of some of the directories and files on your computer. Do they make sense to you? Why do you think they have the permissions they do? Optional coding extension: Write a script to find any files in your home directory (your folder in /Users/) that are writeable by someone other than you. Do these permissions seem safe to you?
- Some programs can be set to execute with the privileges of the file owner rather than the user who is running the program. Why do you think this might be useful? Why is it dangerous?
- When you type "sudo" at the Terminal, you are telling the program to run as the superuser, AKA root AKA Admin. Do some research to find some things that the superuser can do that a normal user cannot.
- AFS has more fine-grained permissions than the standard UNIX filesystem. Instead of rwx (read, write, execute), it has rlidwka (read, lookup, insert, delete, write, lock, administer). Come up with scenarios where you might want to have this level of control instead of being limited to the UNIX permissions.
- Look at the permissions that some of the apps have on your phone. Explain why they might need these permissions.
- Find examples of security breaches that resulted at least in part because programmers had made mistakes and not followed our Authorization principles.
- Pick an example website or app and list some pages where they should be checking to make sure the user should be able to access that page. Optional coding extension: Find a tutorial about how to add authentication to an app (this, for example) and then add some pages where you explicitly check that the user should be able to access them.
Forensics
Computer forensics is all about knowing where to look to find traces of the past. Depending on what the problem is, you might need to piece together a timeline of what happened on a particular computer, recover data that used to be on a hard drive or CD or DVD or USB stick, trace network traffic to its source, or find information hidden in some data or code.
Here is a more formal definition from page 16 of The Digital Forensics Research Workshop:
The use of scientifically derived and proven methods toward the preservation, collection, validation, identification, analysis, interpretation, documentation and presentation of digital evidence derived from digital sources for the purpose of facilitating or furthering the reconstruction of events found to be criminal, or helping to anticipate unauthorized actions shown to be disruptive to planned operations.
The tools and techniques you use are going to be very dependent on the particular problem you are trying to solve. Whatever the system, you want to be familiar with what a normal state of the system looks like, and you want to know what anomalies to look out for. One technique for generating data on what attacks look like are honeypots, machines that no legitimate users are using. Any connections to these machines are by definition suspect and can give you a sense of what attacks might be happening on your real machines, drowned out in a sea of legitimate activity. See these articles and The Honeynet Project.
Below are some tools that might be useful when examining a machine running OSX.
- Log files
- sudo dmesg will show you the recent system messages
- the directory /var/log contains many of the log files for your system
- the Console app pulls together many log files and allows you to filter them
- System State
- sudo ps -ef will show you all processes running on your computer
- top -u will also will show you all processes running on your computer, ordered by the amount of CPU they are using, and top -o mem will order by memory usage
- the Activity Monitor app will give you a view very similar to top
- uname -a will tell you information about your operating system and kernel version
- the System Information app will give you information about the hardware in your system as well as some of the network setting and system preferences
- Filesystem
- ls -lh can give you more information about the files in a directory (Use ls -ldh if you want to see information about the directory itself)
- mdls filename will list the file's metadata keys and their values
- Hitting Command+i in when you have a file selected in Finder will open up a window with metadata information.
- You can look inside of applications, either by using the command line to cd into /Applications/SomeApp.app/Contents or by right clicking on the application in Finder and selecting "Show Package Contents"
- sudo lsof will show you all files that are currently open, and what processes are using them
- df -h will give you information about the hard drive partitions
- du -hs will give you information about how much space each directory is taking up (this can take a long time, if you have a lot in the current directory)
- the Disk Utility app can show you some information about what is on your hard disks
- Sleuth Kit provides various tools that can help you with file system analysis
- Local network stats
- the Network Utility app can show you various stats about your network usage and state. Most of the tabs there are also the names of the command line tools that provide the same or similar information -- netstat, ping, traceroute, whois, finger -- but some have different names. The command line utility for lookup is called dig. For port scan, try nmap --top-ports 100 localhost (Note that running nmap on a machine other than localhost might be considered hostile by the machine's administrator, unlike ping or traceroute. Only run this with localhost.)
- nettop will show you the various network connections that are open and what processes are using them.
- Want to see what your browser is sending in the HTTP requests? Run nc -l 3000 and then visit http://localhost:3000 in your browser.
- Want to look at a network capture (.pcap) file as part of an exercise? You can use https://packettotal.com/ (Most programs that can read pcap files can also capture network traffic. You may not install programs that capture live internet traffic on your school laptop nor run any such programs while connected to the school network.)
Metrics
Additionally, forensics (also called integrity metrics or just metrics) are often used to monitor and protect digital assets, like accounts. For example, let's say you're running a service with millions of accounts, like TikTok, and you want to know if someone is trying to hack an account, or has successfully hacked an account. Some ways you might measure this:
- Password resets: across the entire site, how many people request a password reset each day? If this number spikes suddenly, that might indicate an attacker trying to break into accounts.
- % MFA: what percentage of accounts are protected by multi-factor authentication?
- Superman mode: for an individual account, we can track the IP address where they log in, and know roughly where they are. If they log in from California, and then an hour later log in from Russia, chances are pretty good they're getting hacked by someone in Russia.
- Time of day: most people tend to have predictable patterns of site usage; for instance, some Nueva students might watch a lot of TikTok between 8:15 and 8:55am, and 3:15-3:55 pm, when they're on the train. If someone is logging in and showing activity during a time of day they don't normally do so, their account might be compromised.
- Location history: similar to time of day and superman mode, location history tracks where you log in from; even if your account isn't going superman, if it suddenly starts logging in from another part of the world, it might be compromised.
Forensics Exercises
Respond to at least one of the forensics-related prompts below. Take notes as you do your research.
- What are some of the commands that have been run as sudo recently? Is there anything there that you don't recognize as something you did?
- Try running "traceroute" to some different domains that you often visit. What do you notice about the routes that your packets are taking? How do the ping times to these relate to the routes?
- What processes are taking up the most resources on your machine? Do you recognize them?
- Compare the output of "ls -l" and "mdls" and Finder info for the same file. What pieces of information are duplicated? What are some things that you could only learn from one of these sources? Are there any disagreements between them, and if so, why do you think that is?
- What things are taking up the most space on your harddrive? Does that make sense to you, or should you investigate further?
- What ports are open on your computer? What things are listening on those ports and why?
- Have any other accounts successfully logged into your machine lately? How do you know? How far back can you see?
- Complete some of the forensics-related problems on PicoCTF and briefly explain your solutions.
- Look at the output of "sudo dmesg". What do you notice? What questions do you have? Is there anything in here that worries you?
- Look at the output of "sudo lsof". What do you notice? What questions do you have? Can you find some instances where you feel like you have a good idea why that process is opening that file? (I know a lot of it will likely be indecipherable.)
- (More challenging) Work on forensics-related puzzles or challenges. First, try without looking at the solutions, but feel free to use them for hints when you get stuck.
- http://forensicscontest.com/puzzles Forensics puzzles, with answers
- http://www.honeynet.org/challenges Files from different attacks, to be analyzed. Includes sample solutions.
- https://www.cmand.org/sdn/sdnf.html This challenge involves creating automated forensics tools to go through a memory image and a PCAP file. There is a link to the winning solution.
- http://www.isfce.com/sample-pe.htm Involves an image of a diskette and an image to be run in a virtual machine. Has a written solution.
- https://www.cfreds.nist.gov/ There are various different datasets and tools here. Some are very specific, but others are broader problems.
- http://www.forensickb.com/2010/01/forensic-practical-exercise-3.html This problem involves a USB disk image that once held an important number.
Extra Topics
Reverse Engineering
Reverse engineering is just the practice of trying to figure out what some piece of code or hardware is doing.
If you have access to the source code, this is easier, but as you may know from reading other people's code, it is not always straightforward. Why are these things in a list in this order? What does that '5' mean? What does this website they're accessing do? Without good naming, comments, and documentation, it can be hard to be sure. If the tools used to write or work with the software no longer exist and the developers are not available or don't remember, it can be very hard to figure out how everything worked, as people working with old NASA satellites can tell you.
And that's if the people who wrote the software weren't trying to make it hard to reverse engineer. If people are trying to keep you from understanding the code, either to hide nefarious things the code is doing or to try to keep their proprietary code secret, it can be much harder. Both the high-level source code and the machine code that it compiles to can be obscured. You can make variable and function names hard to read, use more uncommon functions or operations, and go about things in roundabout ways. Here are some examples:
- JavaScript Obfuscator Tool
- Sample Java Obfuscation
- International Obfuscated C Contest Entries
- Hello world programs with no strings
Some reverse engineering doesn't involve code that you have; sometimes it is trying to figure out what some other system is doing. Maybe you realized that software on your computer is contacting some suspicious server. You could look at what it is sending and send something slightly different to see how the server responds, to start to try to figure out what this server is doing and how it works.
For a real-world example of reverse engineering an attack, check out Countdown to Zero Day or The Cuckoo's Egg.
Online Exercises
- Pico CTF: Computer security competition for high school students run by a CS student group at Carnegie Mellon University. You can solve exercises from their previous high school computer security competitions.
- HSCTF: Computer security competition for high school students run by a high school CS club. They have a page with practice problems and solutions.
- Over the Wire has a series of games that start out with learning the command line and move on to security challenges.
- Carolina Zarate, who helped run PicoCTF while at CMU, maintains a great list of exercises
- MIT Computer Security Course has class materials online.